Atari(雅達利) 遊戲作為經典的遊戲始祖,玩家們的樂趣在於如何去獲得最高的分數,打破記錄。而近期,人工智能公司 DeepMind 在官方博客宣布了 AI 挑戰 Atari 遊戲的新進展,稱在57款 Atari 遊戲中實現全面超越人類,是該領域裡的第一次。
 在 DeepMind 最新發布的預印本論文和博客中稱,他們構建了一個名為 Agent57 的智能體,通過在街機學習環境(Arcade Learning Environment,ALE)中學習,從而在 57 個 Atari 遊戲中表現超越人類。如果 Agent57 智能體有如此優秀,那麼將會為構建更加強大的 AI 決策模型奠定基礎,可以進行自動推理環境,實現自動化提升生產力。
在 DeepMind 最新發布的預印本論文和博客中稱,他們構建了一個名為 Agent57 的智能體,通過在街機學習環境(Arcade Learning Environment,ALE)中學習,從而在 57 個 Atari 遊戲中表現超越人類。如果 Agent57 智能體有如此優秀,那麼將會為構建更加強大的 AI 決策模型奠定基礎,可以進行自動推理環境,實現自動化提升生產力。
DeepMind 為什麼選擇用 Atari 遊戲來進行測試呢?其實早在2012年,DeepMind 開發出 Deep Q-Network(DQN),同樣是用於挑戰 Atari 57款遊戲。但當時不能克服四款比較難的遊戲:Montezuma’s Revenge、Pitfall、Solaris 和 Skiing。
 這一次同樣採用遊戲的一部分原因可能是想彌補缺憾,另一部分原因是 Atari 遊戲的一些特點。據悉 Atari 有3個特點,第一是遊戲足夠多樣性,可以用來評估智能體的泛化性能;第二是可以模擬真實環境中的情況;第三是因為 Atari 遊戲由獨立的組織構建,可以有效避免實驗偏見。
這一次同樣採用遊戲的一部分原因可能是想彌補缺憾,另一部分原因是 Atari 遊戲的一些特點。據悉 Atari 有3個特點,第一是遊戲足夠多樣性,可以用來評估智能體的泛化性能;第二是可以模擬真實環境中的情況;第三是因為 Atari 遊戲由獨立的組織構建,可以有效避免實驗偏見。
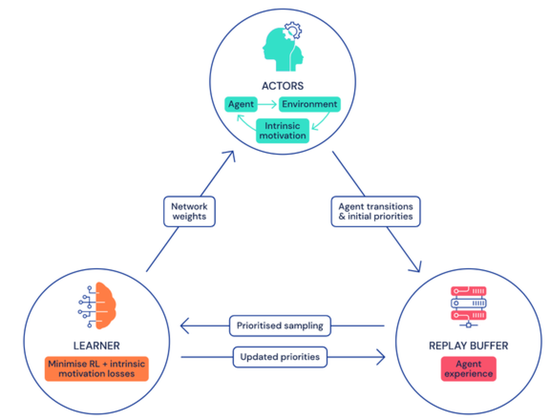
除此之外,DeepMind 在博客上公佈了 Agent57 的框架,採用強化學習算法,在多台電腦上運行。這可以讓 AI 賦能的智能體選擇最大化獎賞去執行指令。 OpenAI 的 OpenAI Five 和 DeepMind 的 AlphaStar RL 智能體分別打敗過 99.4% 的 Dota 2 玩家和 99.8% 的星際2玩家。
Agent57 的學習過程是通過把眾多 actor 信息匯總到可以採樣的一個中央存儲庫中來進行學習。 DeepMind 團隊為了更好的的學習,採用兩種不同的 AI 模型來近似每個狀態動作的價值(state-action value),價值能夠決定智能體的執行指令好壞程度,從而提供評估標準,讓智能體適應性選擇使用哪種策略。
 這個全新的框架模型有著兩個優勢,一是有著策略優先級選擇,讓 Agent57 去分配更多的網絡容量;二是在評估時採用自然的方式來選擇最佳策略。
這個全新的框架模型有著兩個優勢,一是有著策略優先級選擇,讓 Agent57 去分配更多的網絡容量;二是在評估時採用自然的方式來選擇最佳策略。
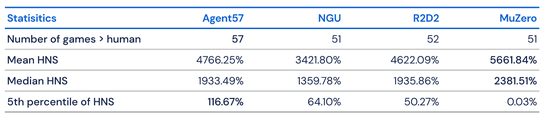
Agent57 在與 MuZero、R2D2 和 NGU 等領先算法的比較中,總體上限更高。在訓練 50億幀後就可以在 51種遊戲上超越人類,而在訓練 780億幀後可以在 Skiing 遊戲上超越人類。
雖然 Agent57 已經在51種遊戲上超越了人類,但是 DeepMind 團隊並不滿於此,向我們透漏了下一步計劃「Agent57 最終在所有基準測試集最困難的遊戲中都超過了人類水平。但這並不意味著 Atari 遊戲研究的結束,我們不僅要關注數據效率,也需要關注總體表現……未來的主要改進可能會面向 Agent57 在探索、規劃和信度分配上。」期待在未來,AI 能夠帶來更多生活上的便捷。








