人工智能的發展突飛猛進,已經不再只是一昧的遵守我們定下的「規矩」行事,而是開始踏上自主學習之路。在兩年前,Google 的人工智能部門 DeepMind 開發的人工智能 AlphaGo 擊敗了世界圍棋冠軍而名聲大增。
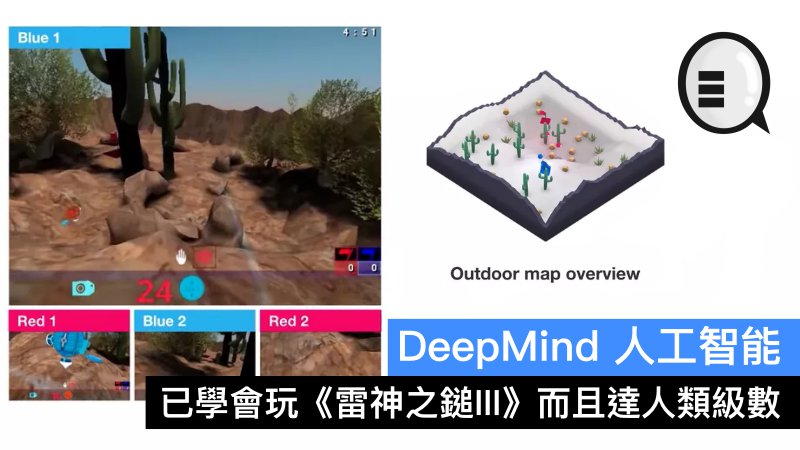 在7月4日,外媒報導了 DeepMind 開發人工智能的新進展。人工智能通過學習,已經學會了玩熱門的多人電子遊戲——《雷神之鎚III》(Quake)。
在7月4日,外媒報導了 DeepMind 開發人工智能的新進展。人工智能通過學習,已經學會了玩熱門的多人電子遊戲——《雷神之鎚III》(Quake)。
 為了這個學習過程,DeepMind 表示,運用了很多的「代理」(Agent:人工智能專業術語,指自主活動的軟件),能夠在從未接受指示的情況下,用「非常高的標準」完成遊戲的學習。但是這個遊戲是第一人稱,規則是兩個團隊互相爭奪對方的旗幟,同時保護自己旗幟不被奪走,遊戲情況千變萬化,還需要與隊員進行合作,對於人工智能的學習挑戰很大。
為了這個學習過程,DeepMind 表示,運用了很多的「代理」(Agent:人工智能專業術語,指自主活動的軟件),能夠在從未接受指示的情況下,用「非常高的標準」完成遊戲的學習。但是這個遊戲是第一人稱,規則是兩個團隊互相爭奪對方的旗幟,同時保護自己旗幟不被奪走,遊戲情況千變萬化,還需要與隊員進行合作,對於人工智能的學習挑戰很大。
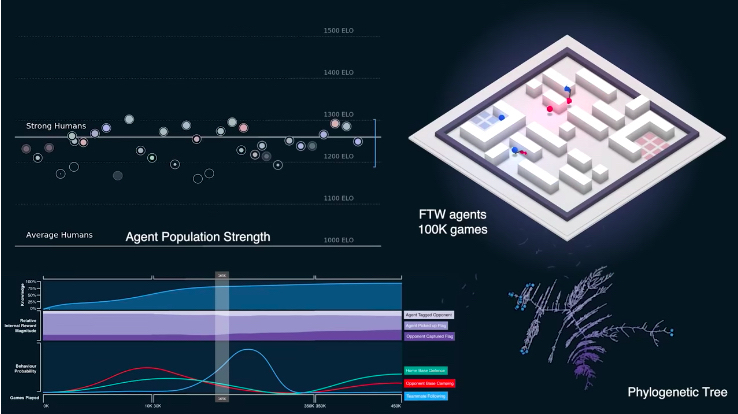
 但是 DeepMind 做到了,開發了創新和強化學習的技術,不僅能夠讓其獨立行動,還能夠配合隊友。就像是 DeepMind 在博客上的聲明「事實上,代理會學習類似人類的行為,例如跟隨隊友並在對手的基地安營扎寨」。在與隨機混合人工智能代理與40名人類玩家的比賽中,可以看到代理勝率居然比人類還高,玩家也反應代理比其他玩家更具有合作能力。
但是 DeepMind 做到了,開發了創新和強化學習的技術,不僅能夠讓其獨立行動,還能夠配合隊友。就像是 DeepMind 在博客上的聲明「事實上,代理會學習類似人類的行為,例如跟隨隊友並在對手的基地安營扎寨」。在與隨機混合人工智能代理與40名人類玩家的比賽中,可以看到代理勝率居然比人類還高,玩家也反應代理比其他玩家更具有合作能力。
最後 DeepMind 在其博客上說「總的來說,我們認為這項工作突顯了多智能體培訓對促進人工智能發展的潛力。」照這樣發展下去,我們可能連遊戲裡的 AI 都打不過了。








