Google 專注於推進AI研究的子公司 DeepMind 昨日發佈了新版本的 AlphaGo 程序,這套系統名為「AlphaGo Zero」。其成功擊敗了去年戰勝韓國圍棋選手李世石的 DeepMind 軟件 AlphaGo Lee。
 據悉,AlphaGo Zero 利用一種名為「強化學習」的機器學習技術,可以在與自己遊戲中吸取教訓。它僅用了三天時間就自行掌握了圍棋的下法,還發明了更好的棋步。這期間,除了被告知圍棋的基本規則,它未獲得人類的幫助。並在三天後成功擊敗去年在圍棋界叱詫風雲的 AlphaGo Lee,戰績為 100 比 0。
據悉,AlphaGo Zero 利用一種名為「強化學習」的機器學習技術,可以在與自己遊戲中吸取教訓。它僅用了三天時間就自行掌握了圍棋的下法,還發明了更好的棋步。這期間,除了被告知圍棋的基本規則,它未獲得人類的幫助。並在三天後成功擊敗去年在圍棋界叱詫風雲的 AlphaGo Lee,戰績為 100 比 0。
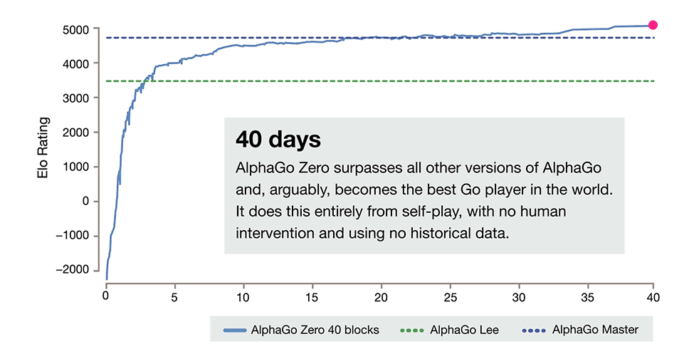
與舊版本的 AlphaGo 相比,AlphaGo Zero 的 AI 智能化主要不是根據已知的人類發展戰略進步,而是經過軟件自身的訓練不斷更新自己的遊戲知識,使自己變得越來越強,而這種做法能使軟件的上限非常之高,它能夠自己創造知識。
目前,AlphaGo Zero 的核心是一組連在一起形成人造神經網絡的「神經元」。對於棋局的每個回合,神經網絡會觀察棋子在棋盤上的位置,並推算接下來的棋步以及這些棋步讓全盤獲勝的概率。每次對弈後,它會更新神經網絡,讓棋藝更精進。而這種設定也讓 AlphaGo Zero 在圍棋比賽中拋除雜念,變得更加純淨。
專家指出,以 AlphaGo Zero 的自學能力及推盤演算能力,如用於醫學研究或科技研究,可能可以解決不少絕症或者未曾解決的科學問題。








